机器翻译和自然语言处理教学设计
自然语言翻译的发展与挑战
自然语言翻译(NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解、处理和生成自然语言文本。随着深度学习和神经网络技术的发展,自然语言翻译取得了巨大进步,但仍面临着一些挑战。本文将探讨自然语言翻译的发展历程、现状以及未来的发展方向,并提出相关建议。
发展历程
自然语言翻译的历史可以追溯到20世纪50年代,最早的机器翻译系统采用基于规则的方法,通过编写大量的语法规则和词典来实现翻译。然而,这种方法在处理复杂的语言结构和多义词时效果有限。
随着统计机器翻译(SMT)的兴起,翻译模型开始基于大规模的双语语料库进行训练,通过统计方法来推断源语言和目标语言之间的概率关系。SMT取得了一定的成功,但仍然存在词序错位、歧义消解等问题。
近年来,随着深度学习技术的发展,神经机器翻译(NMT)成为了主流。NMT利用深度神经网络模型来直接学习源语言和目标语言之间的映射关系,避免了传统方法中需要手工设计特征的缺点,取得了更好的翻译效果。
现状与挑战
尽管NMT在许多任务上取得了巨大成功,但自然语言翻译仍然面临着一些挑战。
1.
数据稀缺性
:NMT模型通常需要大量的双语数据进行训练,然而对于一些语种或领域,可用的数据可能非常有限,导致模型性能下降。2.
多语言翻译
:传统的NMT模型一次只能处理两种语言之间的翻译,对于多语言翻译任务,需要设计更复杂的模型结构和训练方法。3.
语义理解
:尽管NMT可以在一定程度上捕捉语言的语法结构,但对于语义理解仍然存在挑战,特别是在处理复杂的上下文和多义词时。4.
领域适应性
:NMT模型通常在通用数据集上进行训练,对于特定领域的翻译任务,需要进行领域适应性的调整,以提高翻译质量。未来发展方向
为了进一步推动自然语言翻译技术的发展,可以从以下几个方面进行研究和改进:
1.
数据增强与迁移学习
:利用数据增强技术和迁移学习方法,充分利用现有数据资源,提高模型在数据稀缺语种和领域的泛化能力。2.
多模态翻译
:结合图像、语音等多模态信息,开展多模态翻译研究,实现跨语种、跨模态的翻译任务。3.
语义建模与知识图谱
:通过构建更加丰富的语义表示和知识图谱,提升模型对语义信息的理解和表达能力。4.
增强学习与自适应学习
:引入增强学习和自适应学习技术,使模型能够根据环境和任务动态调整策略,适应不同的翻译场景。结语
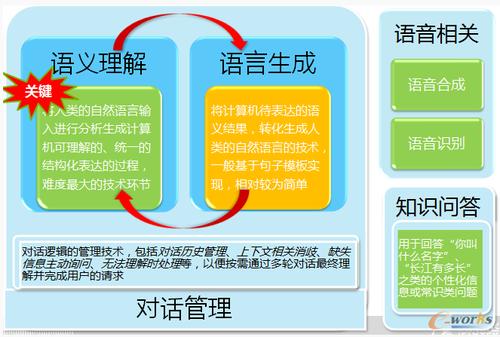
自然语言翻译作为人工智能领域的一个重要研究方向,取得了长足的进步,但仍然面临着诸多挑战。通过持续的研究和创新,相信自然语言翻译技术将会不断突破,为跨语言交流和理解提供更加便利的工具和方法。
免责声明:本网站部分内容由用户自行上传,若侵犯了您的权益,请联系我们处理,谢谢!联系QQ:2760375052